Graphiques multiples (facetting)
Satellite
Visualization
Apprenez à créer plusieurs mini graphiques “par catégorie” en une seule commande
Objectifs
Dans cette session, le but est d’apprendre à :
- créer des graphiques multiples très rapidement avec
{ggplot2} - modifier les paramètres les plus courants pour améliorer l’apparence de ces graphiques
Introduction
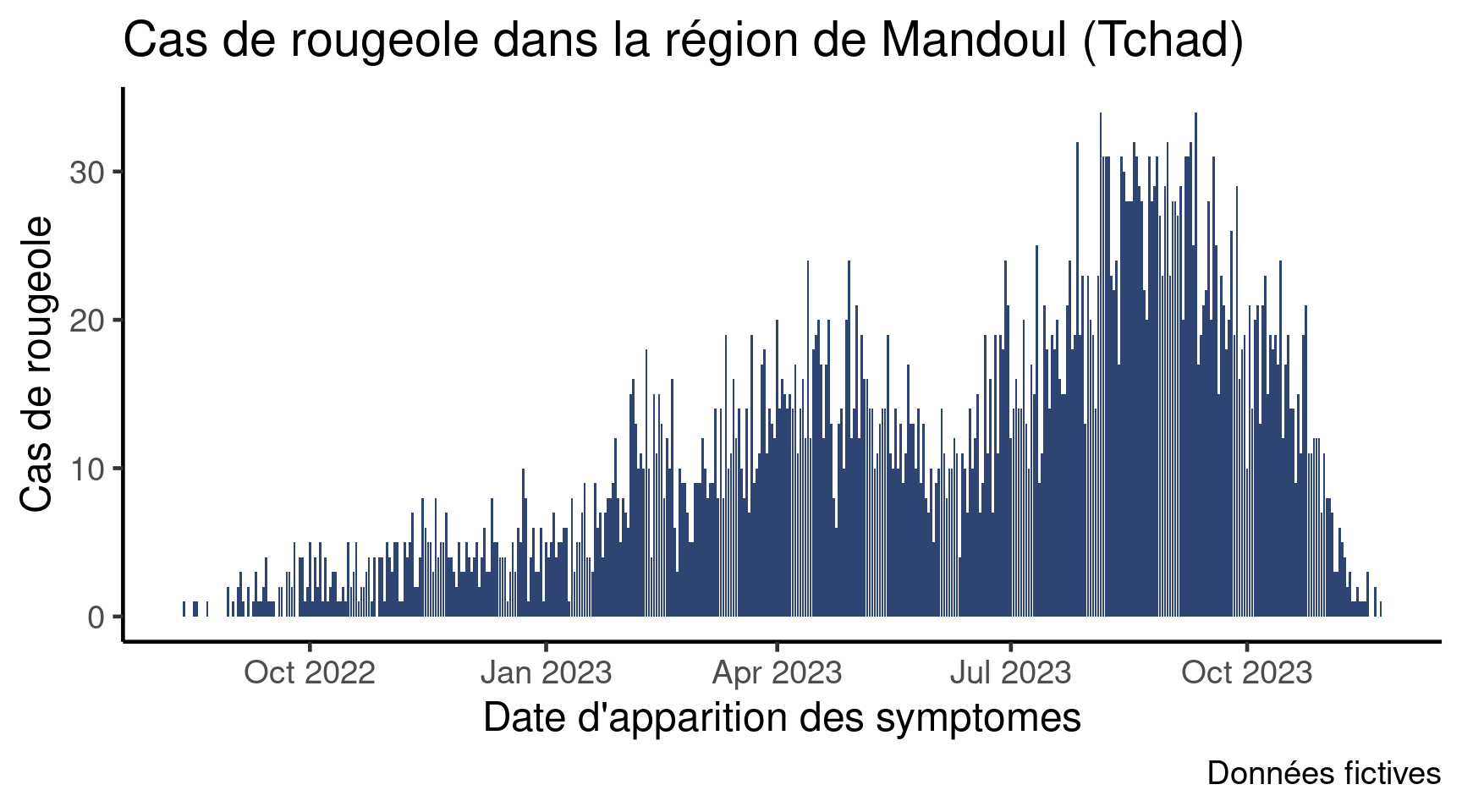
Prérequis : ce satellite s’appuie sur la session sur les courbes épidémiques, durant laquelle nous avons appris à visualiser la distribution quotidienne des cas de rougeoles au cours du temps à l’aide de {ggplot2} :
Ce graphique est très utile, mais ce qui serait encore plus utile serait de pouvoir le décliner rapidement selon les modalités d’une autre variable. Par exemple, nous pourrions vouloir insérer un graphique similaire mais par groupe d’âge dans un rapport de situation [sitrep en anglais]. Il y a plusieurs manières d’arriver à ce résultat. Vous pourriez :
- filtrer un jeu de données pour chacune des classes d’âge, copier-coller le code du graphe et l’adapter pour créer un graphique par classe d’âge
- apprendre à utiliser les boucles
forou les fonctions des famillesapply()oumap()qui servent répéter des actions sans copier-coller - faire confiance à
{ggplot2}pour avoir une solution rapide…
La première option est fastidieuse et source d’erreurs, et nous la déconseillons. La seconde option n’est pas mauvaise en soi : les outils mentionnés sont extrêmement puissants et de bonnes cibles d’apprentissage pour quand vous serez plus à l’aise avec le langage. Mais ils sont trop avancés pour ce petit tutoriel, et une options simple existe déjà dans {ggplot2}.
Mise en place
Nous allons utiliser l’étude de cas sur la rougeole de Mandoul ; si vous n’avez pas encore suivi les autres sessions du cours, veillez à télécharger le dossier du cours avant de continuer.
Pour cette session, nous travaillerons avec les données brutes de la liste linéaire rougeole pour la région de Mandoul.
Créez un nouveau script appelé faceting.R dans votre sous-dossier R (alternativement, vous pouvez rajouter une section au script sur les courbes épis). Ajoutez un en-tête approprié et chargez les paquets suivants : {here}, {rio} et {tidyverse}. Importez ensuite les données propres dans R et enregistrez-les dans un objet df_linelist.
Un graphe par modalité (faceting)
Dans ggplot, “faceting” est est l’action de créer des graphiques en plusieurs parties. La fonction facet_wrap() trace automatiquement un graphique pour chacune des modalités d’une variable. Par exemple, vous pouvez créer une courbe épi par sexe, ou par site. Comme les autres couches d’un ggplot, on l’ajoute à un graphique avec un +. Cela crée une figure avec plusieurs petits graphiques, les fameuses facettes.
Préparer les données
Dans cette leçon, nous expliquerons le code en traçant la courbe par sous-préfecture, et vous tracerez la courbe par groupe d’âge.
Si l’on veut tracer la courbe épidémique par sous-préfecture, il faut que cette variable soit dans le data frame que nous passons à ggplot(). Nous allons donc créer un nouveau jeu de données agrégées qui contient le nombre de patients par jour et par sous-préfecture.
df_pref <- df_linelist %>%
count(date_debut, sous_prefecture,
name = 'patients')
head(df_pref) date_debut sous_prefecture patients
1 2022-08-13 Moissala 1
2 2022-08-17 Moissala 1
3 2022-08-18 Moissala 1
4 2022-08-22 Moissala 1
5 2022-08-30 Moissala 2
6 2022-09-01 Moissala 1Vous devez tracer le nombre de patients par groupe d’âge, donc il vous faut un data frame agrégé par jour et groupe d’âge. Créez-le et enregistrez-le comme df_age. Il a le format suivant :
date_debut age_groupe n
1 2022-08-13 1 - 4 ans 1
2 2022-08-17 5 - 14 ans 1
3 2022-08-18 < 6 mois 1
4 2022-08-22 6 - 8 mois 1
5 2022-08-30 < 6 mois 1
6 2022-08-30 6 - 8 mois 1Tracer le graphique
Maintenant que les données sont prêtes, il ne nous reste plus qu’à tracer le graphique. Examinez le code ci-dessous, il est presque identique à ce que nous avons fait précédemment, à part la dernière ligue qui crée les facettes :
df_pref %>%
ggplot(aes(x = date_debut,
y = patients)) +
geom_col(fill = "#2E4573") +
labs(x = "Date d'apparition des symptomes",
y = "Cas de rougeole",
title = "Measles cases in Mandoul (Chad)") +
theme_classic(base_size = 15) +
facet_wrap(vars(sous_prefecture)) # Graphique par sous-pref !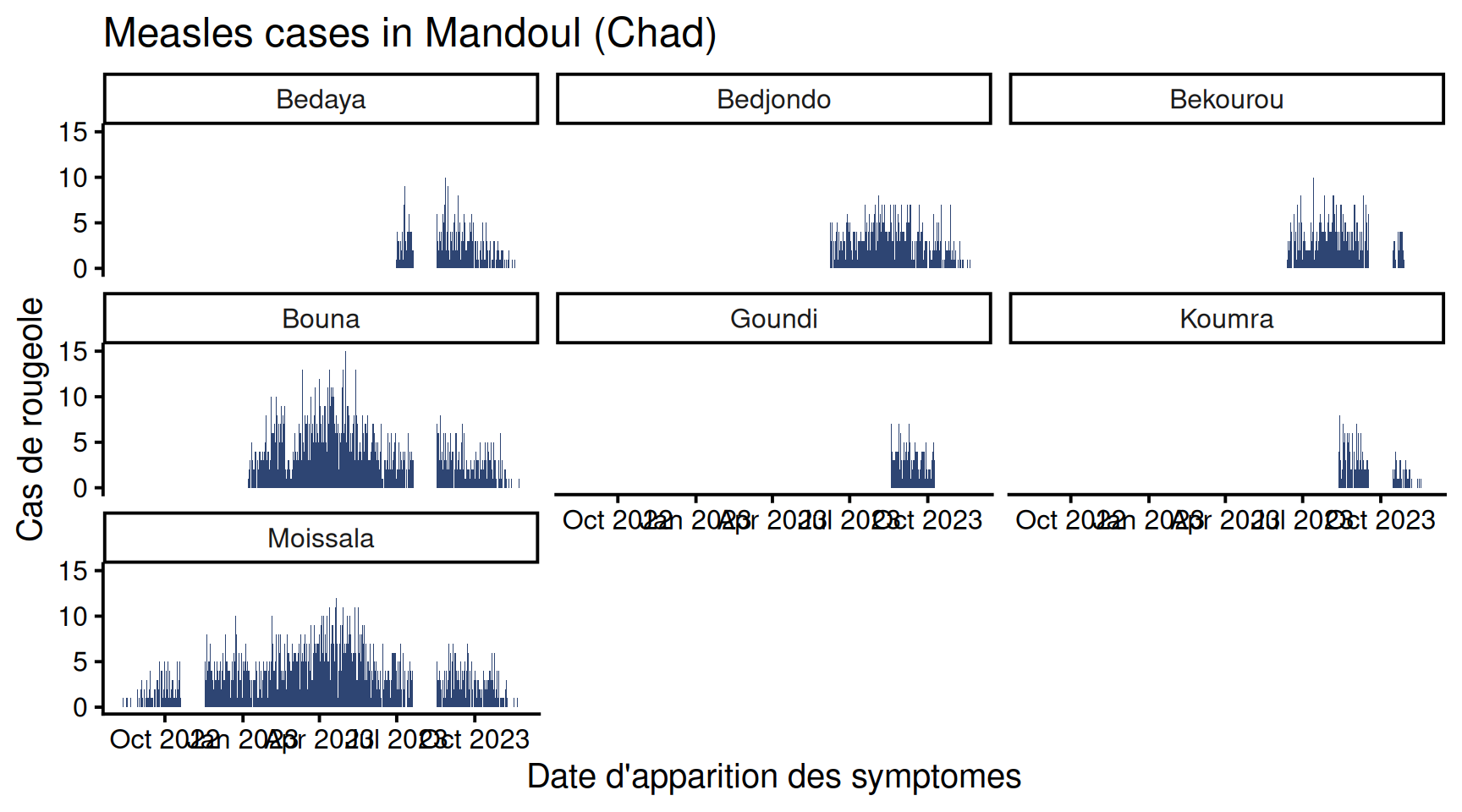
J’espère que vous êtes soufflés ! D’un point de vue syntaxe, la fonction facer_wrap() prend en argument le nom de la variable catégorique qui nous intéresse, enrobé dans la fonction vars().
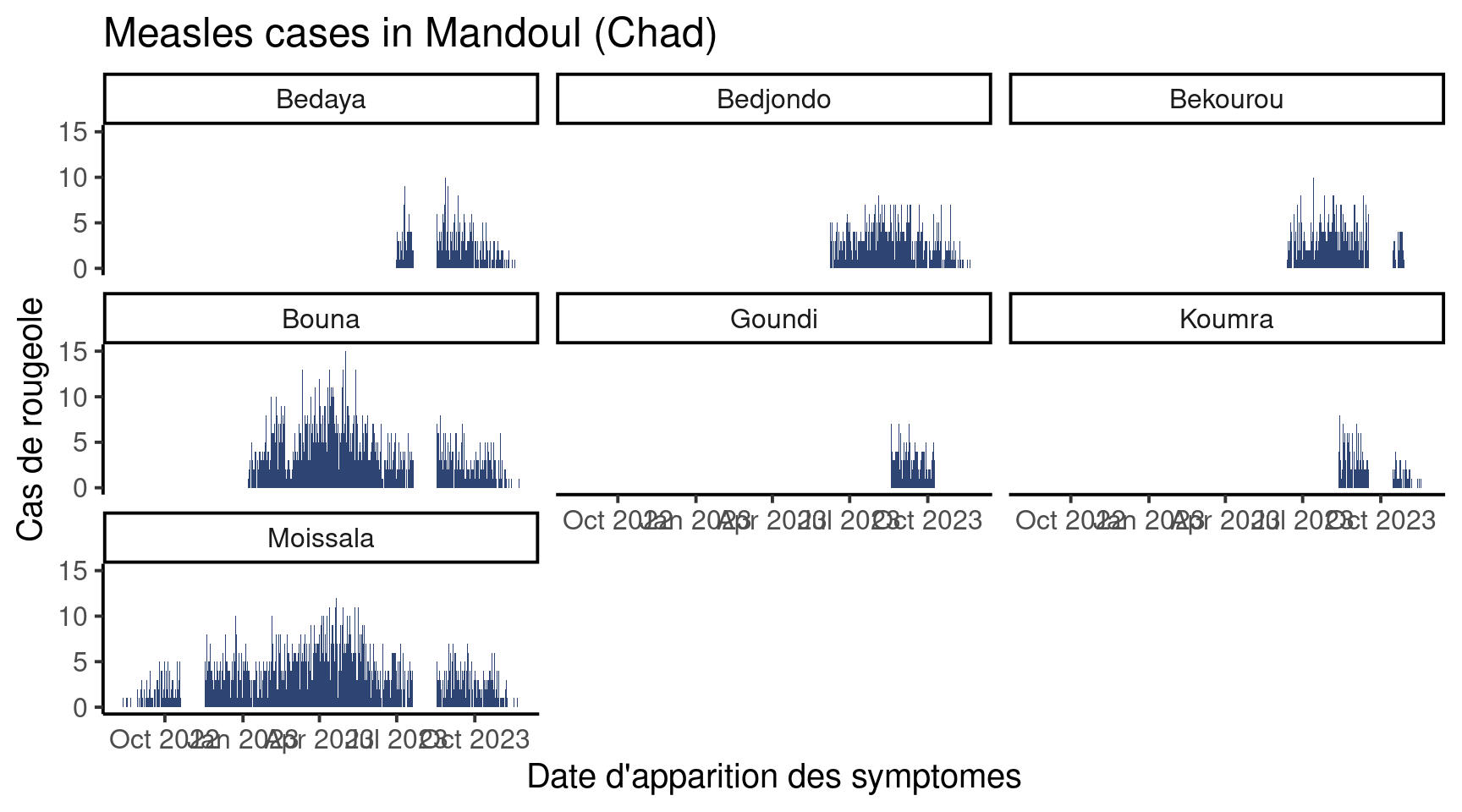
A votre tour. Tracez le graphe par classe d’âge. Il devrait ressembler à ça :
Modifier l’aspect des facettes
Ouvrez la page d’aide de la fonction sur le site du paquet pour avoir la liste des arguments acceptés. Nous allons aborder certains d’entre eux à présent.
Nombre de lignes ou de colonnes
Les arguments nrow et ncol vous permettent de décider combien de facettes il doit y avoir sur une ligne, ou sur une colonne.
Si nous voulions avoir toutes les facettes sur deux lignes :
df_pref %>%
ggplot(aes(x = date_debut,
y = patients)) +
geom_col(fill = "#2E4573") +
labs(x = "Date d'apparition des symptomes",
y = "Cas de rougeole",
title = "Cas de rougeole dans la région de Mandoul (Tchad)") +
theme_classic(base_size = 15) +
facet_wrap(vars(sous_prefecture),
nrow = 2) 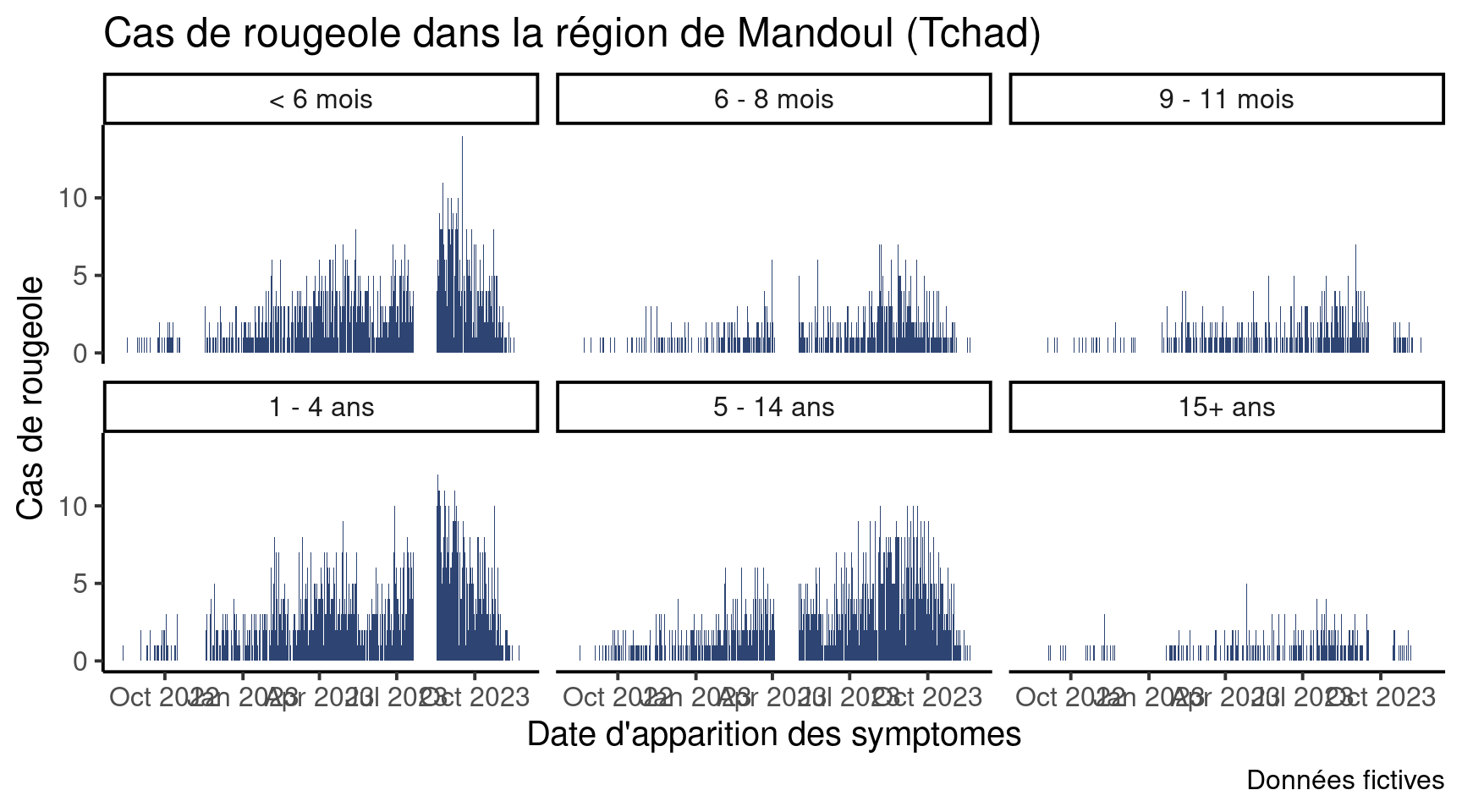
Ou au contraire nous pouvons forcer le nombre de lignes à 4 pour avoir une figure tout en hauteur :
df_pref %>%
ggplot(aes(x = date_debut,
y = patients)) +
geom_col(fill = "#2E4573") +
labs(x = "Date d'apparition des symptomes",
y = "Cas de rougeole",
title = "Cas de rougeole dans la région de Mandoul (Tchad)") +
theme_classic(base_size = 15) +
facet_wrap(vars(sous_prefecture),
nrow = 4) 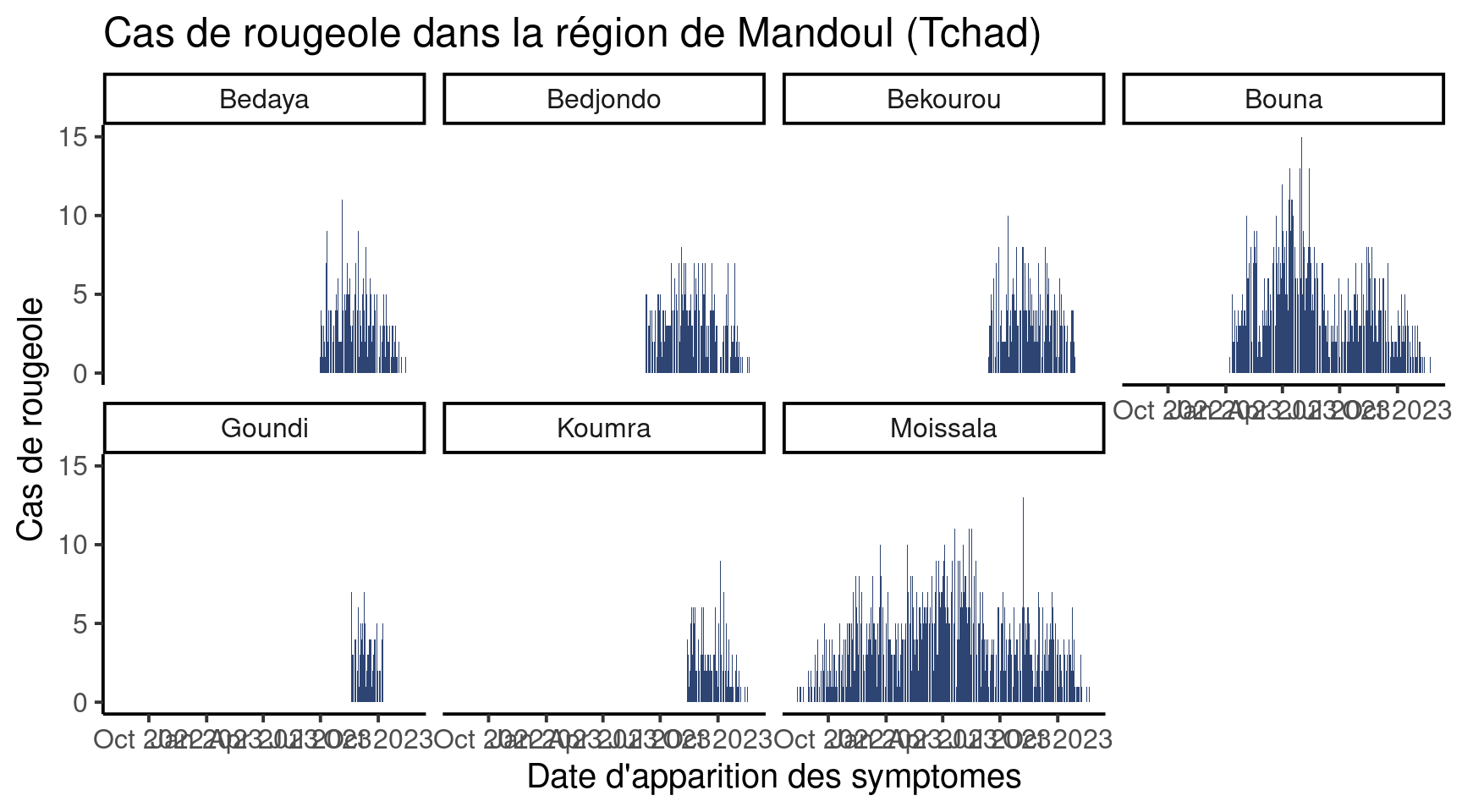
Utilisez un des deux arguments présentés ci-dessus pour créer un graphe avec trois colonnes.
Plages des axes
Avez-vous remarqué que les valeurs minimales et maximales en x et en y étaient les mêmes pour toutes les facettes ? C’est que par défaut facet_wrap() fixe les plages pour les deux axes. Ce comportement est raisonnable pour pouvoir comparer les facettes et éviter d’induire le lecteur en erreur.
Ceci étant dit, si vous êtes plus intéressé par la forme de la courbe à l’intérieur de chaque facette que par la comparaison des catégories entre elles, il peut être approprié de zoomer sur les données disponibles en autorisant des axes indépendants (“libres” de varier). Prévenez alors le lecteur que les facettes ne sont pas toutes à la même échelle.
L’argument scales [échelles] accepte les valeurs suivantes :
-
"fixed": la valeur par défaut, x et y à la même échelle pour toutes les facettes -
"free_x": l’échelle de x peut varier entre facettes -
"free_y": l’échelle de y peut varier entre facettes -
"free": les deux axes peuvent varier entre facettes
Contrastez le graphe précédent avec celui-ci :
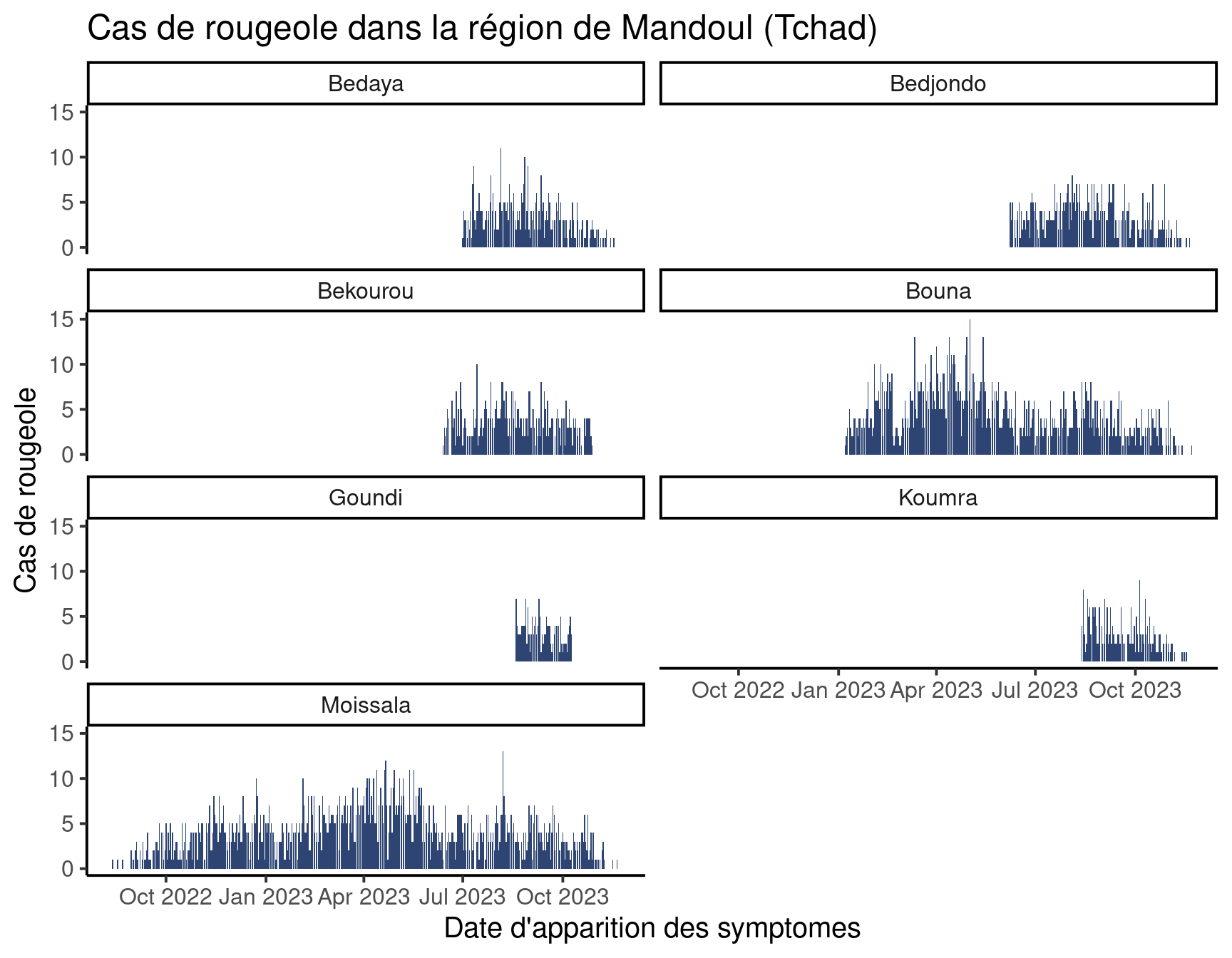
Nous avons autorisé à avoir des échelles indépendantes sur toutes les facettes en x et en y, pour zoomer sur les cas dans chaque sous-préfecture.
Tracez la courbe par groupe d’âge, avec l’axe des abscisses fixe et l’axe des ordonnées libre.
C’est fini !
Bravo, vous avez créé vos premiers graphiques en fonctions d’une variable catégorique. Cela devrait vous être très utile. Sachez que la fonction fonctionne aussi avec d’autres types de graphes créés par {ggplot2}.
Si le graphique est très large, il est possible que les étiquettes des dates ne soient pas très lisibles en x, et c’est le cas pour certains des exemples. Cela peut être contrôlé, et le sujet est abordé dans un autre satellite !